Docker镜像、Spark支持多表...Apache SeaTunnel 2.3.8版本将带来的惊喜

Apache SeaTunnel 2.3.8版本即将于大家见面,近日,Apache SeaTunnel PMC Member 范佳在社区的交流会上为大家提前透露了关于这个新版本即将进行的功能与特性更新概况,详细内容如下:
SeaTunnel 简介
SeaTunnel是一个高性能的开源分布式数据集成系统,支持各种数据源的实时流式和离线批处理,适用于海量数据的集成。它具有以下特点:
- 海量连接器:支持100+种数据源和存储系统。
- 多引擎支持:兼容多种数据处理引擎,包括SeaTunnel Zeta Engine、Spark和Flink。
- HTTP支持:可以通过HTTP接口进行数据集成。
- 流批一体:同时支持流处理和批处理。
- 流速控制:能够控制数据流的速率。
- 自动建表功能:自动根据数据结构创建表。
2.3.8 版本新功能与特性
在即将发布的2.3.8版本中,社区将对SeaTunnel进行以下功能和特性的更新:
Docker 镜像
新版本将提供官方版本的 Docker 镜像,将包含几乎所有的 Connector,用户无需下载安装包,通过直接通过拉取镜像,可以更快地运行 SeaTunnel,减轻 SeaTunnel 部署的复杂度。
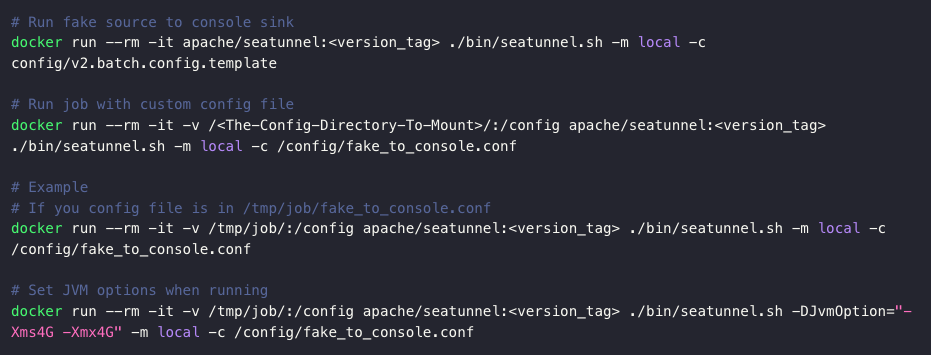
- 通过命令构建镜像:对于本地部署,并且有定制化需求的用户,可以通过命令行构建镜像;
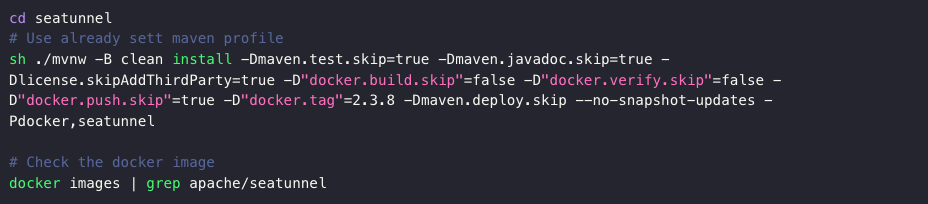
- 通过命令启动服务:支持通过命令启动服务进行分布式部署,以及提交任务和查询任务状态等;当然。也可以通过 rest-API 提交任务。

- 通过命令提交服务:

Spark 支持多表
目前,SeaTunnel 仅支持 Zeta Engine 对多表的支持,新版本将增加 Spark 引擎对多表的支持,可以自动识别并自动运行多表任务。
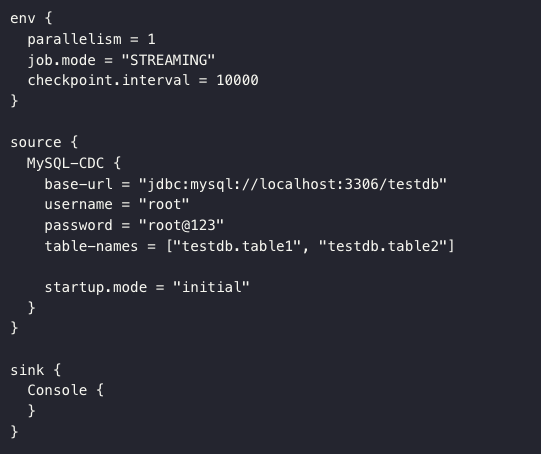
另外,Flink 对于多表的支持已经在推进之中,感兴趣的朋友欢迎来 GitHub 参与共建。
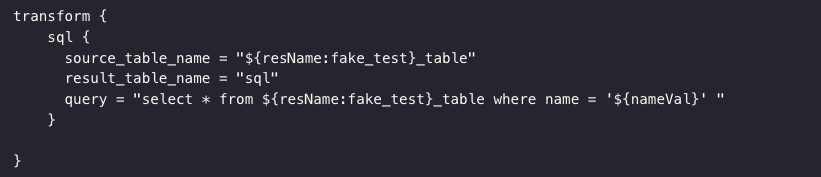
Config 参数支持默认值
目前,SeaTunnel 允许在 config 参数进行变量配置,但每个变量需要手动配置。新版本则将允许在配置参数中使用默认值,提高了配置的灵活性。
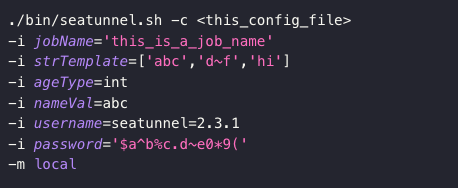
适配 Prometheus 进行集群监控
此前,SeaTunnel 提供了接口来获取任务运行的指标,新版本将支持适配 Prometheus 进行集群监控。Prometheus 将定期拉取 SeaTunnel 的集群任务状态,并以可视化界面展示出来,以更便利地监控集群的状态,及时发现问题。
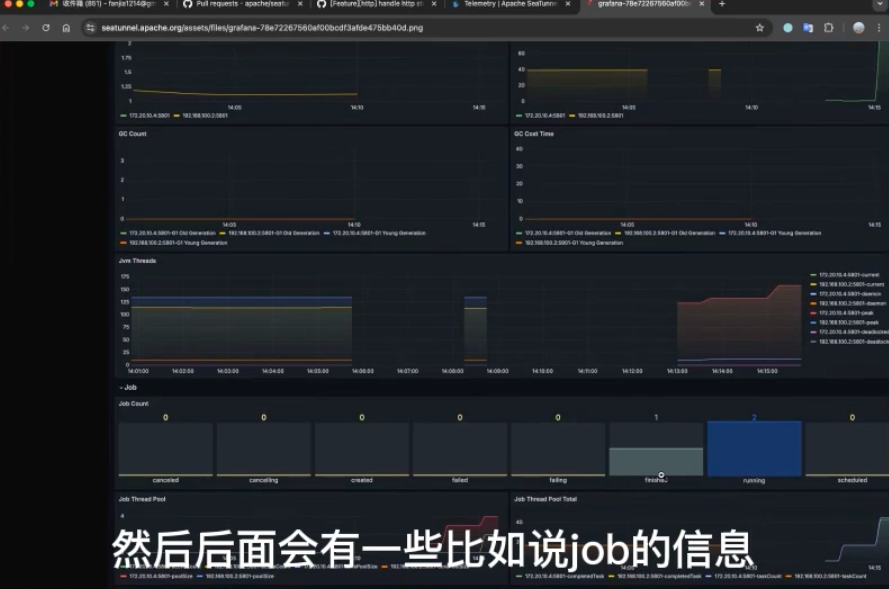
Dashboard展示
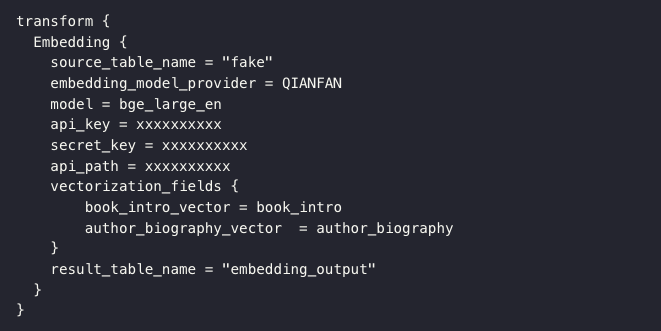
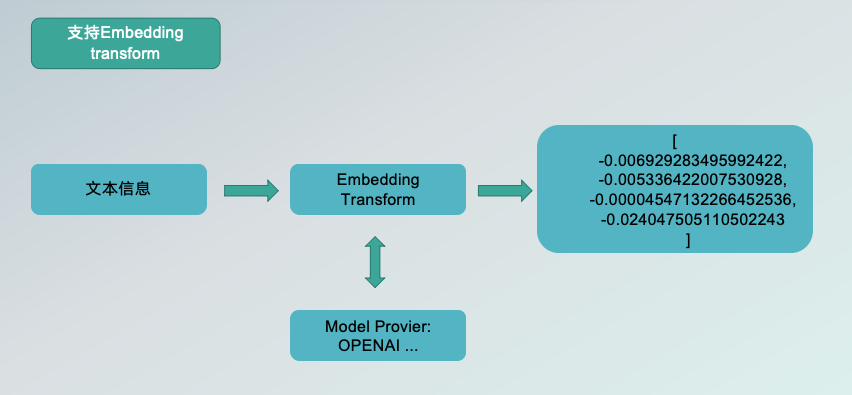
添加 Embedding transform
通过 Embedding transform,支持将机器学习模型嵌入到数据转换过程中,把原始字段转换成向量值,再存储到相应的机器学习数据库。目前,SeaTunnel 支持的机器学习模型提供商包括豆包、千帆、OpenAI。
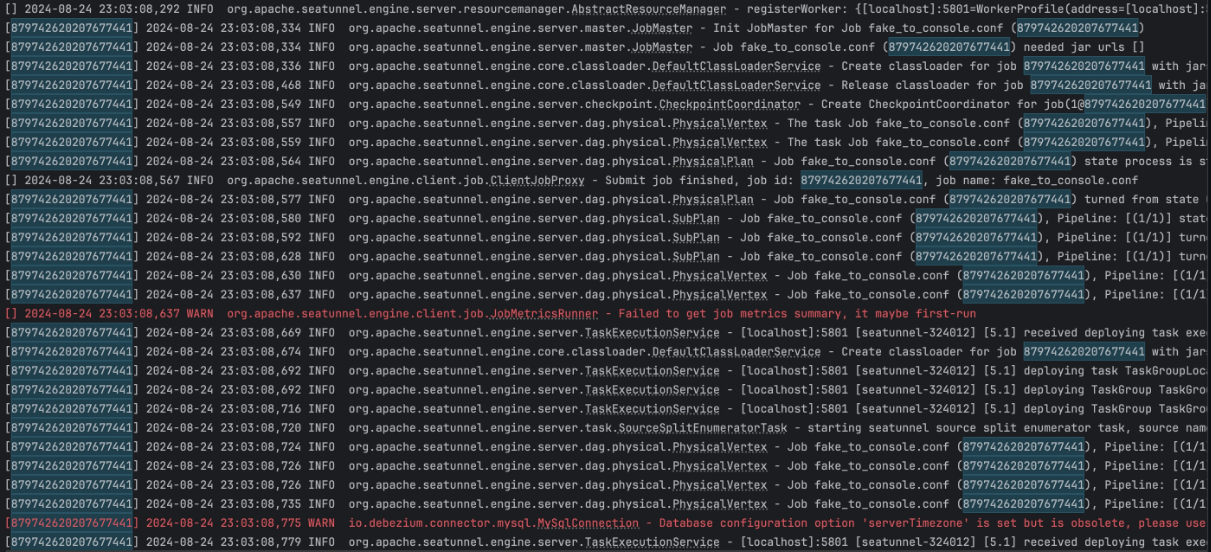
Job 级别日志过滤查看
增加了Job级别的日志过滤和查看功能,可以通过三种方式实现日志过滤。
第一种是通过把 Job ID 打印到日志的最前面,用户可以通过搜索 Job ID 来找到属于此 Job 的所有日志,这样可以把日志过滤出来,解决当多任务并发时,一旦其中一项任务出错,通过日志来排查问题相对比较困难的难题。
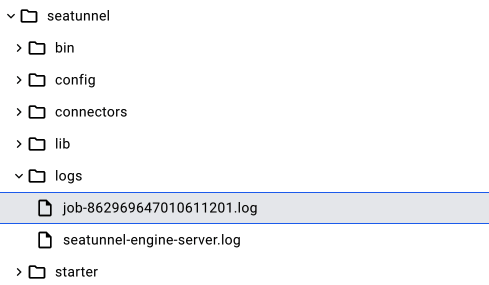
第二种是根据 Job ID 拆分文件,通过修改 log 配置文件,很多文件都是配置好的,只需要简单修改,任务就会在每一个 Job 打一个日志文件。相同的 Job ID 会被归类到同一个文件下,这样就方便大家查找日志文件。
修改log4j2.properties配置文件示例:
...
rootLogger.appenderRef.file.ref = routingAppender
...
appender.file.layout.pattern = %d{yyyy-MM-dd HH:mm:ss,SSS} %-5p [%-30.30c{1.}] [%t] - %m%n
...
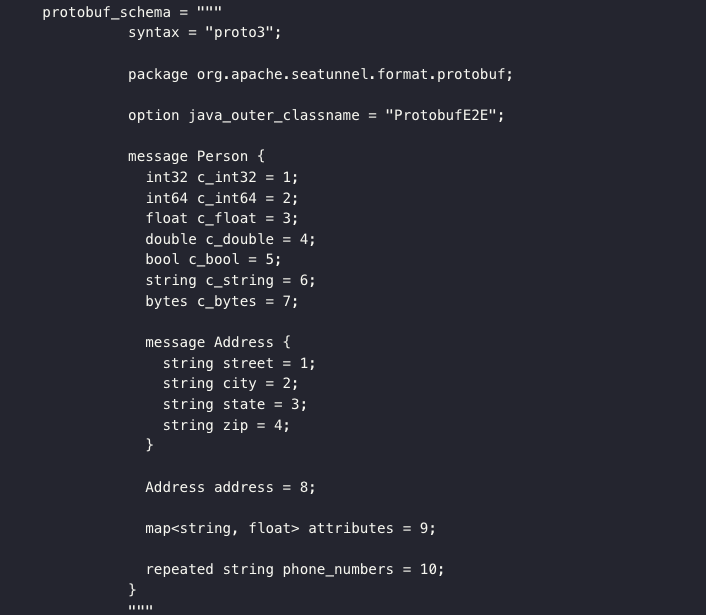
Kafka 支持读取/写入 Protobuf 类型数据
增强了 Kafka 连接器对 Protobuf 数据格式的支持,在 Kafka 连接器下增加对 Protobuf 数据类型的定义,进行数据读取和写入。
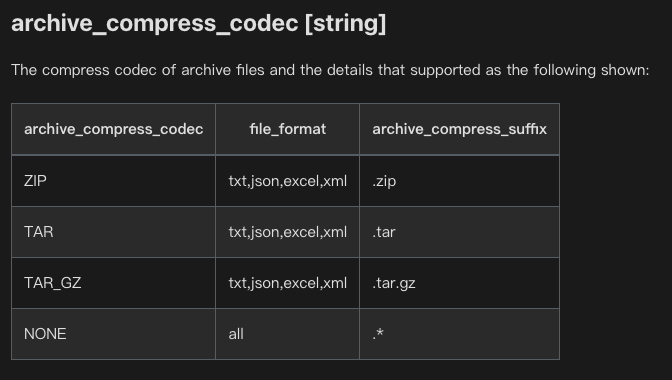
文件支持读取压缩包
增加了对压缩文件格式的读取支持,省去了解压缩的步骤。
其他功能
此外,新版本还将移除对系统表的过滤,允许用户读取系统表;增强对Paimon流式读取和动态桶写入的支持。
如何获取最新版本和参与贡献
下载
SeaTunnel 2.3.8 版本预计将于 10 月初发布,届时可关注 SeaTunnel 官网下载页面 获取最新版本的SeaTunnel。
参与贡献
-
邮件列表
通过发送邮件到 [email protected] 订阅SeaTunnel开发邮件列表,参与社区讨论和发版投票。 -
GitHub
访问 Apache SeaTunnel GitHub 仓库 追踪社区最新动态,提交bug报告和功能请求。
结语
SeaTunnel 2.3.8 版本的发布将带来一系列新功能和改进,使得数据集成更加高效和灵活。感谢所有贡献者的努力,让 SeaTunnel 成为一个更加强大的数据集成工具。
更多信息请访问 SeaTunnel 官网。
本文由 白鲸开源 提供发布支持!